I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models



In the rapidly evolving domain of digital content generation, the focus has shifted from text-to-image (T2I) models to more advanced video diffusion models, notably text-to-video (T2V) and image-to-video (I2V). This paper addresses the intricate challenge posed by I2V: converting static images into dynamic, lifelike video sequences while preserving the original image fidelity. Traditional methods typically involve integrating entire images into diffusion processes or using pretrained encoders for cross attention. However, these approaches often necessitate altering the fundamental weights of T2I models, thereby restricting their reusability. We introduce a novel solution, namely I2V-Adapter, designed to overcome such limitations. Our approach preserves the structural integrity of T2I models and their inherent motion modules. The I2V-Adapter operates by processing noised video frames in parallel with the input image, utilizing a lightweight adapter module. This module acts as a bridge, efficiently linking the input to the model's self-attention mechanism, thus maintaining spatial details without requiring structural changes to the T2I model. Moreover, I2V-Adapter requires only a fraction of the parameters of conventional models and ensures compatibility with existing community-driven T2I models and controlling tools. Our experimental results demonstrate I2V-Adapter's capability to produce high-quality video outputs. This performance, coupled with its versatility and reduced need for trainable parameters, represents a substantial advancement in the field of AI-driven video generation, particularly for creative applications.
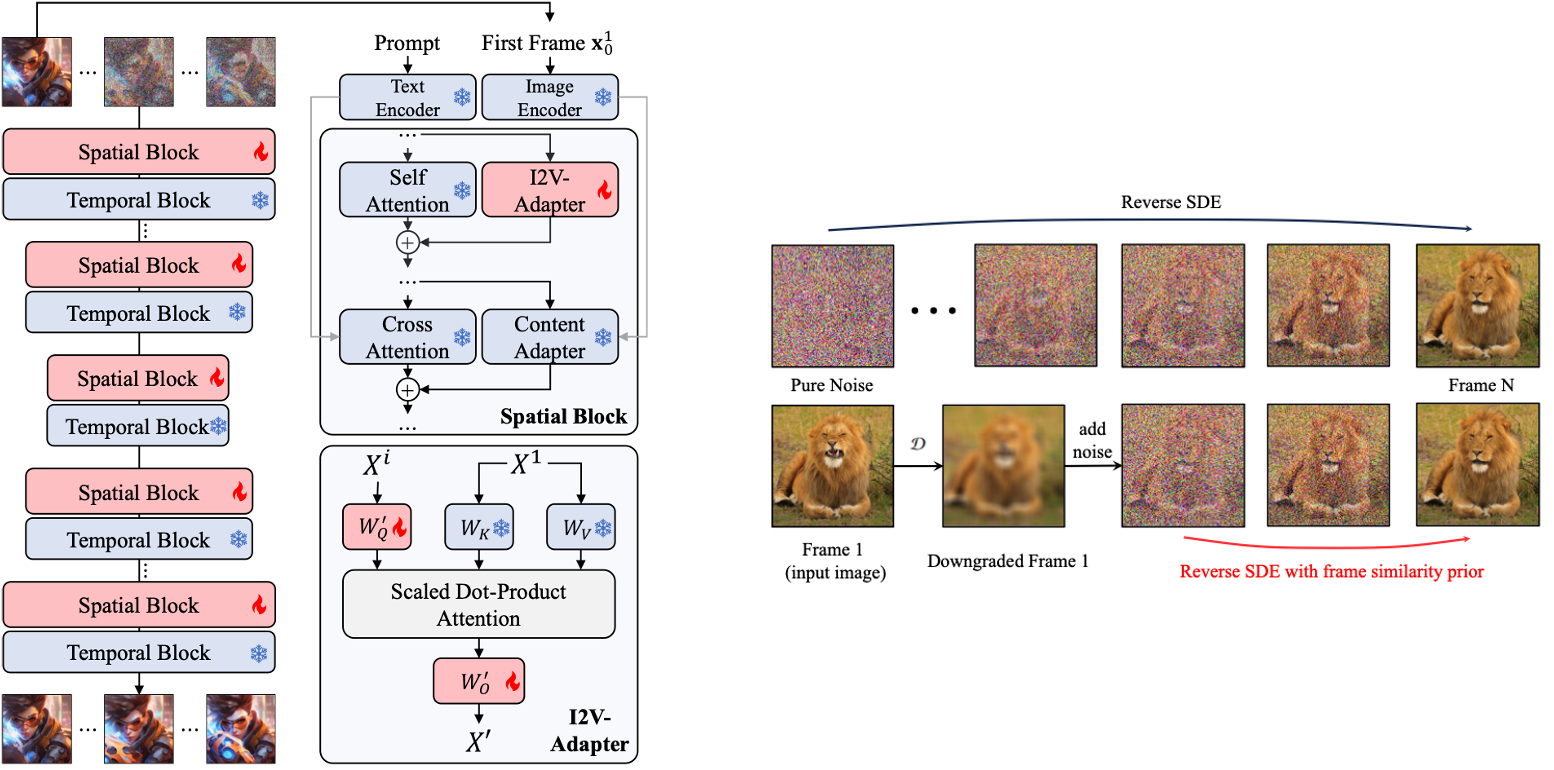
Given a reference image and a text prompt, our goal is to generate a video sequence starting with the provided image. This task is particularly challenging as it requires ensuring consistency with the first frame, compatibility with the prompt, and preserving the coherence of the video sequence throughout. We introduce I2V-Adapter, a plug-and-play module to transfer a T2V diffusion model into an I2V diffusion model.
The core design of I2V-Adapter is a decoupled attention mechanism to parallelly process the input image and the noised images. We zero-initialize the output layer of I2V-Adapter to ensure that the model starts as if no modifications have been made. We also leverage a content adapter to provide high-level semantic information to enhance the condition.
To stablize the generation process, we also propose an additional frame similarity prior. Our key assumption is that, on a relatively low Gaussian noise level, the marginal distributions of the
noised first frame and the the noised subsequent frames are adequately close. At a high level, we assume that in most short video clips, all frames are structurally similar and become indistinguishable after being corrupted with a certain amount of Gaussian noise.














































Project page template is borrowed from DreamBooth.